DEEPSCAN - GDPR


What is GDPR?
The General Data Protection Regulation (GDPR) is a regulation approved by the EU Parliament on 14th April 2016. Any organization that works with EU residents’ personal data, irrespective of the organization’s location, must meet these obligations.
What is Personal Data?
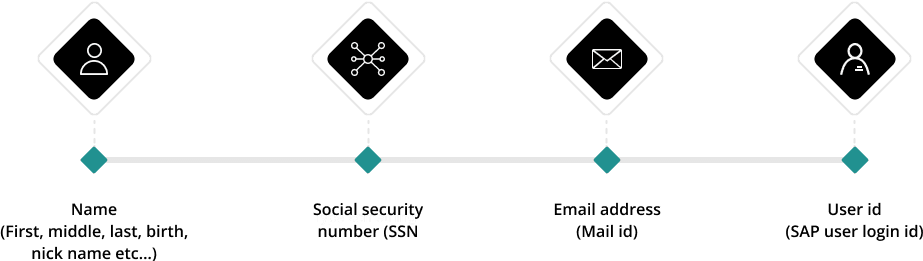
Any information relating to an identified or identifiable natural person (‘data subject’) - GDPR Article 4. The person can be identified either directly or indirectly by identifiers such as Name, Social Security Number (SSN), Email Address, Location, Bank Details, etc.
Where can we find Personal Data in SAP?
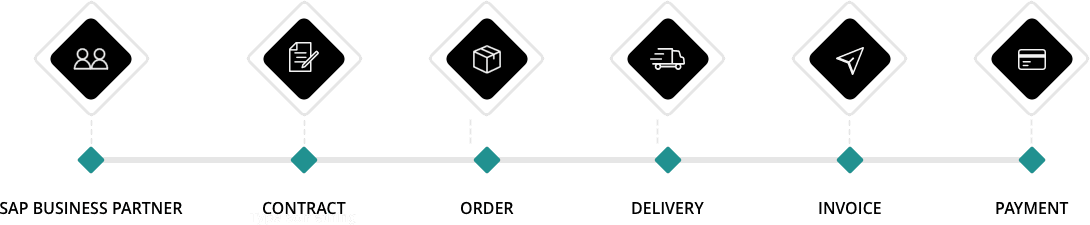
What happens if a company or organization is not GDPR compliant?
There are two tiers of administrative fines that can be levied as penalties for non-compliance:
- Up to €10 million, or 2% annual global turnover - whichever is higher.
- Up to €20 million, or 4% annual global turnover - whichever is higher.
How can a company or organization be GDPR compliant?

Focus Area
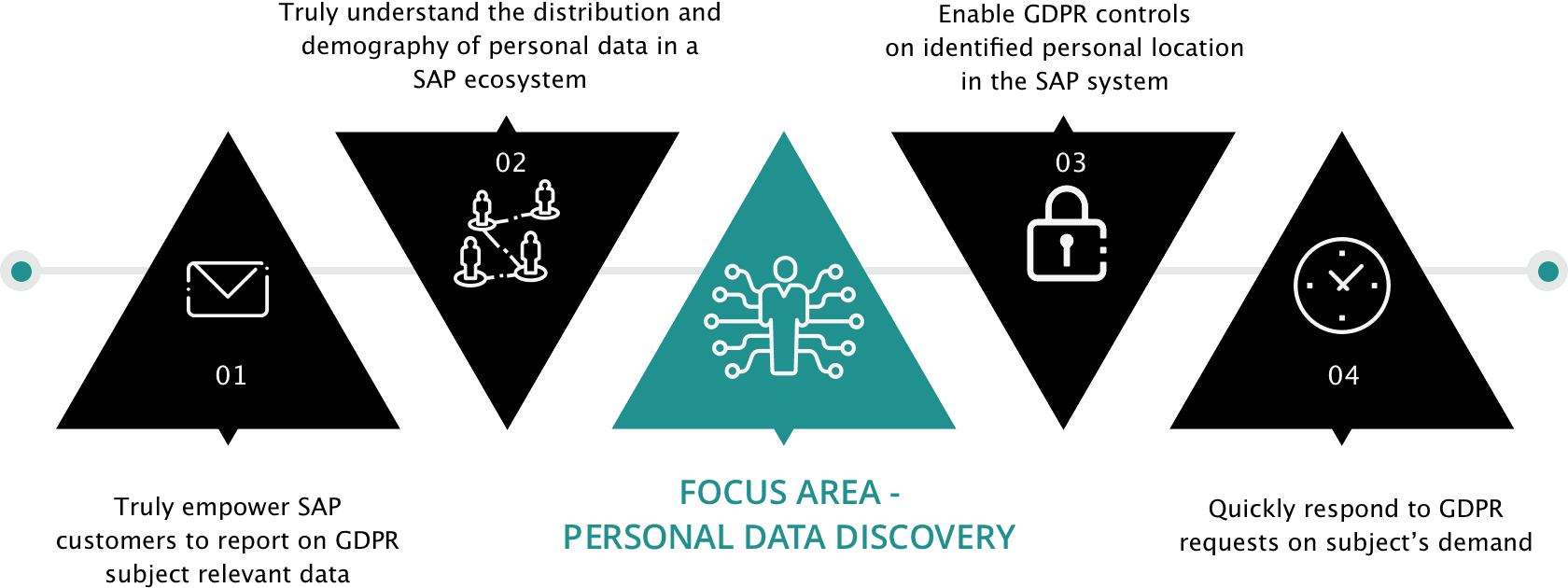
Purpose
Identify the list of all tables in which personal data related attributes are stored along with content in SAP tables (Both Standard & Custom Tables).
For GDPR compliance, it is important that you can know where your SAP ERP and SAP CRM systems store Personal Data. You can use GDPR Deep Scan to find the GDPR relevant data quickly and easily without the need to invest in additional infrastructure. GDPR deep scan acts like an SAP Add-on solution without introducing a need for scaled resources.
How Deep and accurate the tool search results
Our solution locates all the instances of the GDPR related attributes in the sap system from all the available tables in minutes.
It helps you to discover the data maintained in multiple tables based on our GDPR metadata repository set prepared for SAP ERP AND CRM systems after quite a bit of intelligent research and screening of SAP’s data models.
Personal Related Data Attributes considered
Systems in Scope
- CRM
- ECC
- HR (Future Scope)
- S4Hana On-Premise & Cloud (Future scope with HANA text analytics)
Benefits of Using this tool
- Easy to locate all the instances of the GDPR attributes in your SAP system.
- The report can be run in the background.
- Doesn’t require any additional servers/hardware/software to set up.
- It is just like an add-on tool, which can be downloaded and installed.
Navigate to transaction code SE38 and select the GDPR report

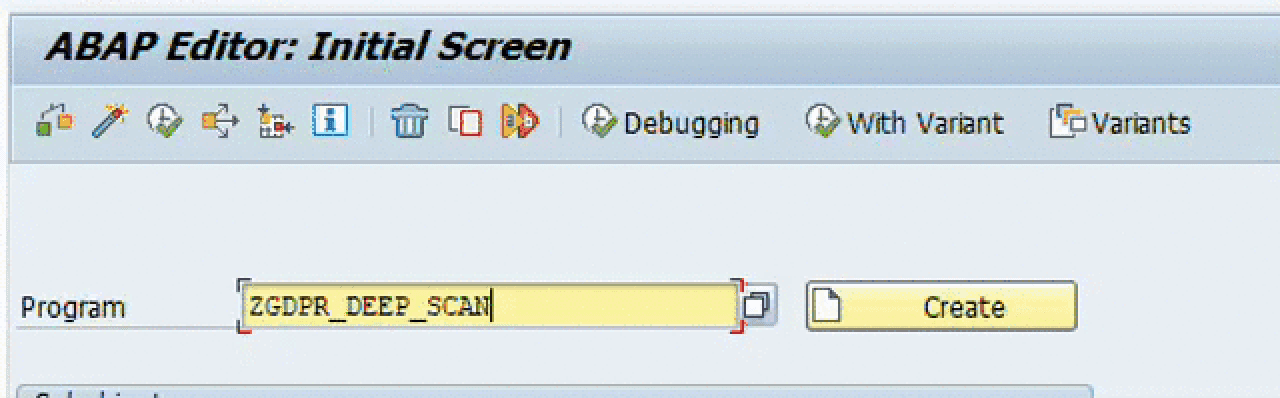
List of GDPR attributes would be available, Select the search attribute field and enter the search text and execute the report.

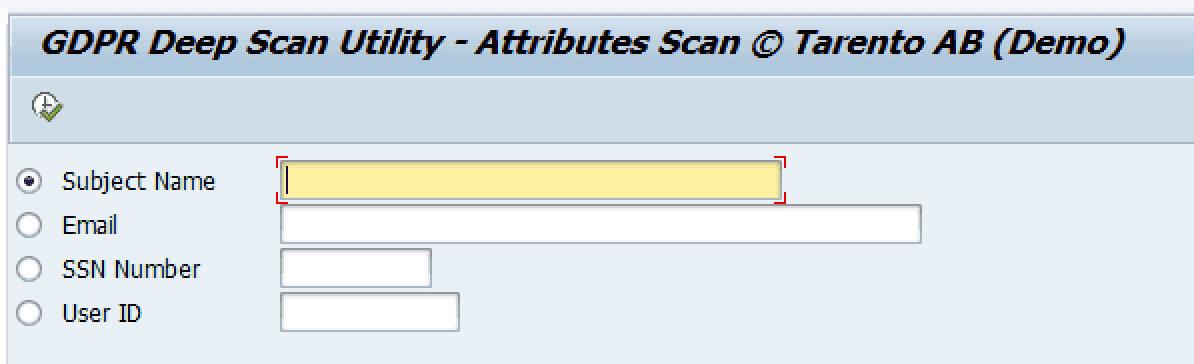
For example, here we are searching based on user id

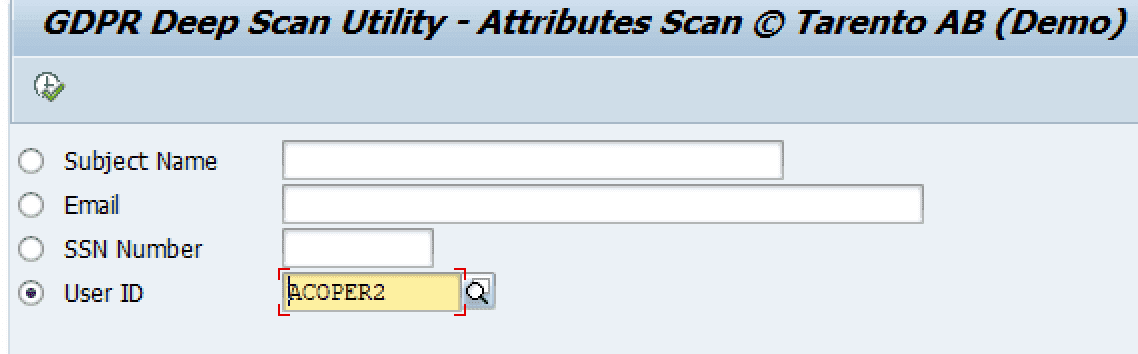
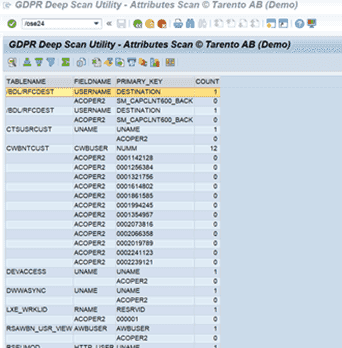
The result would display the
- list of all tables in which the entry is available.
- Count of entries in each table.
- The field name in which the entry is present.
- Even the primary key field of the table is displayed.

The report can be export to a local file
Report can be executed in background too.
- List of the table names along with respective field names in which the GDPR attributes shall be present.
- The GDPR metadata repository is prepared after extensive research of all available data elements in SAP systems (ECC, CRM).

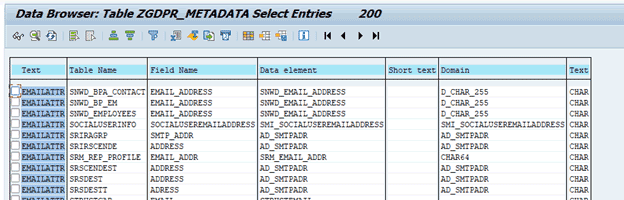
1. With help of ABAP Dictionary Tables
- DD04T – Identify the relevant data elements for each GDPR attribute based on the description or text
- DD03L - Identify the fieldnames based on the data elements
- DD02L – Identify relevant tables based on the fieldnames and data elements
(Note – Only transparent tables and fieldnames of CHAR Data type are considered)
2. Using the below keywords, initial set of data elements has been filtered from the total of 4+ Million data elements in DD04T For Name & User Id -
"user, first, last, display, person, business, legal, second, associate, birth, middle, surname, full, family, forename, employee, sponsor, dependent, maternal, father, mother, child, paternal, enterer, signer, translator, physician, format, consult, provident, pension, supervisor, doctor, initiator, Author, representative, lawyer, writer, reporter, responsible, inspector, name1, name2, name3, by, witness, creator, delete, account, patient, examiner, injured, personnel, doctor, liable, bank,
physician, recipient, beneficiary, payee, payer, passenger, nickname, initials, short name, authorized, authorized, contact, participant, full, partner, Business Partner, creditor, debtor, third party, 3rd, party, 3, auditor, instructor, tenant, grantee, guardian, guarantor, vendor, supplier, consumer, producer, customer, owner, who, chief, manager, sender, receiver, signed, signature, correspondence, participant, insured, child, payer, payee, driver, member, contact, applicant, spouse, wife, parents, sender, receiver, title, trustee"
3. For Email Address -
"Mail"
For SSN - "Employee Identification Number (EIN), identification, pin, number, SSN, social, security, customer number, personnel number, personal id, account number, Personnel no. Pers.no., tax number"
Using the below queries, the data elements are searched for each keyword.
SELECT
ROLLNAME, DDTEXT, REPTEXT, SCRTEXT_L, SCRTEXT_M, SCRTEXT_S
FROM DD04T WHERE DDLANGUAGE = 'E' AND
(UPPER(DDTEXT) LIKE '%NAME%' OR UPPER(REPTEXT) LIKE '%NAME%' OR UPPER(SCRTEXT_S) LIKE '%NAME%'
OR UPPER(SCRTEXT_M) LIKE '%NAME%' OR UPPER(SCRTEXT_L) LIKE '%NAME%')
- The data elements are further filtered out by going through the description/text, data type and length one by one and only relevant data elements is considered.
- From the final list of data elements, only the relevant fieldname and tables are considered.
SELECT TABNAME, FIELDNAME, ROLLNAME, DOMNAME, DATATYPE, LENG
FROM DD03L WHERE TABNAME IN (
SELECT DISTINCT TABNAME FROM DD02L WHERE TAB class = 'TRANSP') AND DATATYPE = 'CHAR' AND
ROLLNAME IN (LIST OF DATA ELEMENTS FILTERD OUT USING THE ABOVE KEYWORDS))
How to setup this tool?
Maintenance / Support


Support & maintenance
Support availability
Entitled to version upgrades


Customer customization
Additional personal data attributes
Customer specific visualizations etc


Additional solution packages
Additional system like SAP CRM
Also other system packages available on demand


GDPR deep scan tool foundation
Rapid deployment solution packages - SAP ERP/CRM
3 personal data attributes (Name, E-mail address.)
Full system scan, Standard and Z-tables
-
If I search for a customer’s name “Harald”, will only a selection of tables/fields with the right attributes be searched?
Yes, the right tables and fields for this name attribute are stored in our GDPR metadata repository. -
If there are Z_ solutions developed and there are Z_ data tables/fields created, will we know if they are related to “name”? What if the developer has given very strange names?
Our deep scan search scripts pick the data elements / fields with the nearest description as well. If the custom data elements/ fields are absolutely misnamed, then we have a gap of course. -
In some cases, the users can write a name or a social security number in a field that is not designed for that information. Like if you write the social security number in a fee-text field. Does our current search cover this? If we search for my number will it be discovered in fields not classified as SSN-fields?
No. Then we should go to a more sophisticated unstructured search. That's a different line of solution that’s typically un-available for non-hana based SAP systems. -
As a result of the above question – If the answer is no today: Could this be some kind of "extended" search?
Yes, but the complexity raises, but doable on a consulting mode. Out of the box, SAP doesn't offer the capability for unstructured search, we will then need to use database specific mechanisms or trex for non-hana databases. -
Another question related to this is if we can create an extensive search for certain sensitive words that is searched for in the full environment. It could be words indicating political opinion, labor union membership etc. Also, words regarding an individual’s health etc. This is very critical GDPR information and is not allowed to exist without a clear approval from the individual. All companies want to make sure no such information is stored without their knowledge.
We could take a repository of free text fields and run the extended search on those fields only. However, it is highly unlikely this kind of information is in an enterprise system. We either use text analysis with open source solutions like elastic, or if the customer is on HANA already, use the HANA native text analysis functions. However, this shall fall presently beyond the purview of the tool based on structured data.
Discover personal information in your SAP ERP, S4HANA and CRM systems with our GDPR Deepscan tool now.

