What is Data fabric?

A data fabric is an end-to-end data integration and management architecture that creates a unified, governed view of an organisation's data across every system, cloud and location it sits in. Rather than physically moving data into one place, a data fabric uses active metadata, knowledge graphs, semantic models and machine learning to discover, connect and serve data where it already lives. The result is consistent access for every user and application, in real time, without forcing every team onto the same database.
Gartner has consistently named data fabric a strategic technology trend for enterprise data and analytics teams, particularly as organisations scale AI and real-time decision support on top of fragmented data estates.
How a data fabric works: the six core layers
A modern data fabric is built as six interlocking layers rather than a single product:
- Data management. Governance, security, lineage and access policies applied consistently across every connected source.
- Data ingestion. Connectors that pull from transactional databases, data lakes, warehouses, SaaS APIs and streaming sources, structured and unstructured.
- Data processing. Refinement, cleaning and quality controls so only fit-for-purpose data is exposed to downstream consumers.
- Data orchestration. Transformation, integration and harmonisation across batch and real-time pipelines.
- Data discovery. Active metadata, knowledge graphs and ML-driven recommendations that surface related datasets and unblock data scientists who would otherwise spend weeks finding what they need.
- Data access. A virtualised interface that lets analysts, applications and AI models consume data through APIs, BI tools and self-service catalogues, with permissions enforced at the access boundary.
The key idea: data stays where it already lives. The fabric stitches it together through metadata and APIs rather than mass migration.
Key characteristics of a modern data fabric
- Unified view across hybrid and multi-cloud. One semantic layer over on-premise, cloud and edge sources.
- Active metadata and knowledge graphs. Continuously updated metadata drives discovery, classification and lineage.
- Built-in governance and security. Consistent policies for access, masking, encryption and audit, applied across every source.
- Data virtualisation. Data appears as a single enterprise source to consumers, regardless of physical location.
- Real-time access. Streaming-friendly architecture that supports sub-second decisions where the use case demands it.
- AI-augmented integration. Machine learning recommends datasets, identifies duplicates and suggests join paths.
Data fabric vs data mesh: the difference that matters
The two terms are often confused. They solve overlapping problems but with different operating models.
A data fabric is a technology-led architecture. It abstracts over distributed sources using active metadata and virtualisation so the central data team can deliver a unified experience without moving data. Ownership often stays central.
A data mesh is an organisational and architectural pattern. Domain teams own and publish their own data as products. The mesh provides federated governance and a self-serve platform so domains can serve each other without going through a central queue.
In practice, large enterprises increasingly combine the two. The fabric provides the technical substrate (active metadata, knowledge graphs, virtualisation, governance). The mesh provides the operating model (domain ownership, data-as-a-product). One is the how, the other is the who.
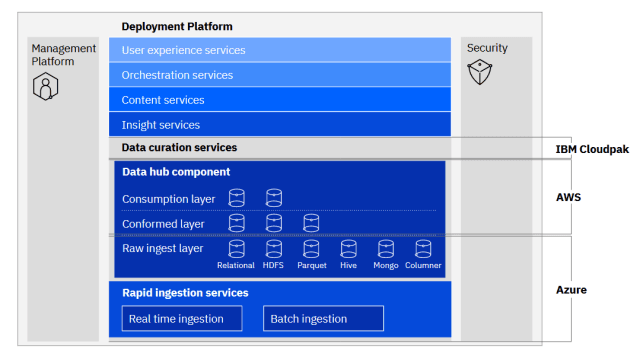
Benefits of a data fabric architecture
- Faster integration, lower maintenance cost. Industry adopters report sharply reduced integration design, deployment and ongoing maintenance effort, because the fabric automates work that data teams previously hand-built per pipeline.
- Democratised data access. Self-service catalogues, supported by ML-driven recommendations, broaden access well beyond the central data team without compromising governance.
- Stronger data protection. Centralised policies for access control, masking and encryption travel with the data rather than being reapplied in each pipeline.
- AI-ready foundations. Active metadata and knowledge graphs make retrieval-augmented generation and agentic AI workflows materially more reliable, because the model has a clear, governed view of what data exists.
- Lower data gravity. Workloads can run closer to the data they need, instead of dragging large datasets across regions and clouds.
Common data fabric use cases
- Customer 360 and personalisation, stitching customer data across CRM, transactional, behavioural and service systems for a single profile.
- Fraud detection, correlating real-time transactions with historical patterns and external feeds across the enterprise.
- Predictive and preventative maintenance in manufacturing and energy, blending IoT telemetry with maintenance records and supplier data.
- Risk and compliance reporting in banking, insurance and pharma, where fragmented sources have historically slowed regulatory output.
- AI and agentic workflows, where retrieval, grounding and observability all benefit from a governed semantic layer.
When to choose a data fabric
A data fabric earns its keep when an organisation has:
- Data spread across multiple clouds, on-premise systems and SaaS applications.
- A growing set of AI and analytics use cases blocked by data discovery and trust gaps.
- Regulatory pressure that demands consistent lineage, masking and access control.
- A central data team that needs to scale beyond a per-project, per-pipeline operating model.
The technology choice (active metadata catalogue, virtualisation layer, knowledge graph, governance platform) matters, but the work that determines success is the semantic and governance modelling that sits on top. That is the layer where the fabric stops being software and starts being a working part of how the business runs.
For enterprises planning that journey, Explore Tarento´s Data & Analytics practices and the DataVolve platform.


Why is Snowflake successful today?


