The Engineer’s Guide to Better Software Design Decisions

Software design principles are not theoretical rules reserved for architecture documents. They shape the daily decisions that determine whether systems remain maintainable, scalable, and reliable over time: how abstractions are drawn, how behavior is assembled, how state is managed, and how failure is anticipated.
Teams that build maintainable, evolvable systems are separated not by talent, but by consistent application of a small set of foundational principles—principles that shape flexibility, testability, and long-term delivery confidence.
1. Interfaces vs. Abstract Classes in Software Design
The Real Difference Between an Interface and an Abstract Class
The difference is not syntax. It is design intent.
An interface defines what a component can do—not how it does it. It is a pure contract: method signatures, expectations, and invariants. It enforces no behavior and shares no state.
An abstract class defines both what and some of how. It provides shared state or default behavior while leaving specific parts to subclasses.
| Interface | Abstract Class | |
|---|---|---|
| Models | Role or capability | Base implementation |
| Relationship | "Can do" | "Is a" |
| State | None | Allowed |
| Multiple use | Yes (a class can implement many) | No (single inheritance) |
| Best for | Loose coupling, mocking, plugin seams | Controlled behavior reuse |
When to use an Interface vs. an Abstract Class?
Use an interface when:
- You want multiple unrelated types to share a capability
- You need easy mocking for tests
- You are defining a stable seam between services or modules
- The implementation will vary significantly across types
Use an abstract class when:
- There is a genuine "is-a" relationship between types
- Shared state or default logic is intentional and stable
- You want to enforce a partial implementation across a controlled hierarchy
A simple rule: if you feel tempted to add fields, protected helpers, or evolving logic—you have left interface territory.
What Happens When Teams Choose Wrong?
A payments team built a PaymentProcessor as an abstract class with shared retry logic, metrics, and config. Over time, new providers required different retry semantics. Changes for one broke others. Teams added flags, overrides, and conditionals.
Eventually, a refactor split the design into a clean PaymentProcessor interface with separate composable retry strategies. It cost months of effort—effort that a correct initial abstraction would have avoided.
Interfaces and abstract classes serve different design goals. One optimizes for flexibility and decoupling. The other optimizes for controlled reuse. The cost of choosing wrong is paid later, with interest.
2. Composition Over Inheritance for Maintainable Code
Why Inheritance Creates Long-Term Rigidity
Inheritance creates tight coupling by design. A child class is permanently bound to its parents' behavior, assumptions, and future changes.
Over time, this leads to:
- Base classes are becoming god objects that multiple teams depend on
- Changes to shared logic breaking unrelated subclasses
- Fear-driven development where nobody wants to touch the hierarchy
- Slower onboarding because new engineers must understand the full tree before making changes
What Is Composition and How Does It Work?
Composition models behavior through delegation, not extension.
Instead of a PremiumOrder that is an Order, an Order has a PricingStrategy, a DiscountPolicy, and a FulfillmentRule—each independently configurable and testable.
| Inheritance | Composition | |
|---|---|---|
| Relationship | "Is a" | "Has a" |
| Coupling | Tight | Loose |
| Behavior change | Requires new subclass | Swap the component |
| Testing | Tests full hierarchy | Tests components independently |
| Runtime flexibility | Limited | High |
This is why patterns like Strategy, Decorator, and Adapter exist. It also explains how modern systems are built: feature toggles, rule engines, policy-based authorization, and pluggable workflows are all composition-heavy designs.
When Did Skipping Composition Create Real Production Pain?
A payments team modeled payment methods with deep inheritance: Payment → CardPayment → InternationalCardPayment → InternationalCardWithOffers. Each new regulation or offer required a new subclass.
- Changes to fraud logic broke unrelated flows
- Testing combinations became expensive
- Deployments touched five classes for a single offer change
The fix was compositional: a Payment type with independently configurable ValidationRules, FeeCalculators, and OfferApplicators. What had taken weeks started taking hours.
Composition Over Inheritance is not about avoiding inheritance. It is about earning the flexibility to change behavior without dismantling structure.
3. Why Immutability Improves Software Reliability
What Problem Does Mutable State Actually Cause?
Most production bugs do not come from complex algorithms. They come from a state that changes when nothing is expected of it.
Common symptoms include:
- Race conditions under concurrent load
- Inconsistent reads across threads or services
- Flaky tests that fail intermittently
- Incidents that cannot be reproduced locally
- "Works on my machine" behavior that disappears in staging
The cost is disproportionate. At scale—more concurrency, more teams, more services—shared mutable state becomes the primary source of unplanned debugging time.
What Does Immutability Mean in Practice?
Immutability means that once an object is created, it never changes. A different value requires a new object, not a mutation of the existing one.
This provides:
- Predictability — a reference always points to the same values, no matter when or where it is accessed
- Thread-safety by default — immutable objects can be shared across threads without locks
- Safe caching — immutable values cannot be accidentally corrupted after being cached
- Cleaner APIs — functions with immutable inputs tend to become pure: same input, same output, no hidden side effects
- Safer service boundaries — passing immutable data across layers or services prevents leaky mutations
Immutability shows up in practice as:
- Value objects (
Money,Address,DateRange) that cannot change after construction - Copy-on-write patterns and builders instead of setters
- Event-sourced or append-only logs where history is extended, never rewritten
- Configuration objects built once and shared safely across the application
What Does a Real Immutability Failure Look Like?
A pricing team reused a PricingContext object across requests to reduce allocations. The object had setters for currency, customer tier, and discount rules.
Under load, concurrent requests began sharing the same instance due to a pooling optimization:
- Discounts leaked between customers
- Some users saw premium pricing; others received employee discounts
- Logs looked correct because the context mutated after logging but before billing
- The bug took days to reproduce
The fix was one design decision: make PricingContext immutable and build a new instance per request.
Immutability is not a style preference. It is a reliability strategy.

4. Idempotency in APIs: Designing for Safe Retries
Why Systems That Ignore Retries Fail in Production
Some of the most expensive bugs in software do not come from scaling problems. They come from simple actions happening more than once. A customer clicks "Pay" twice. A mobile app retries after a timeout. A message broker redelivers an event. Suddenly, one request becomes two orders, two charges, or two confirmation emails.
Modern systems are built on retries. Browsers retry, mobile apps retry, load balancers retry, and background workers retry. In theory, retries improve reliability. In practice, they create duplication, financial loss, and broken customer trust when the system is not designed to handle repeated requests safely. This matters most in payment systems, booking platforms, and order management—where duplicate execution has a direct business impact.
How to Design APIs That Handle Repetition Safely
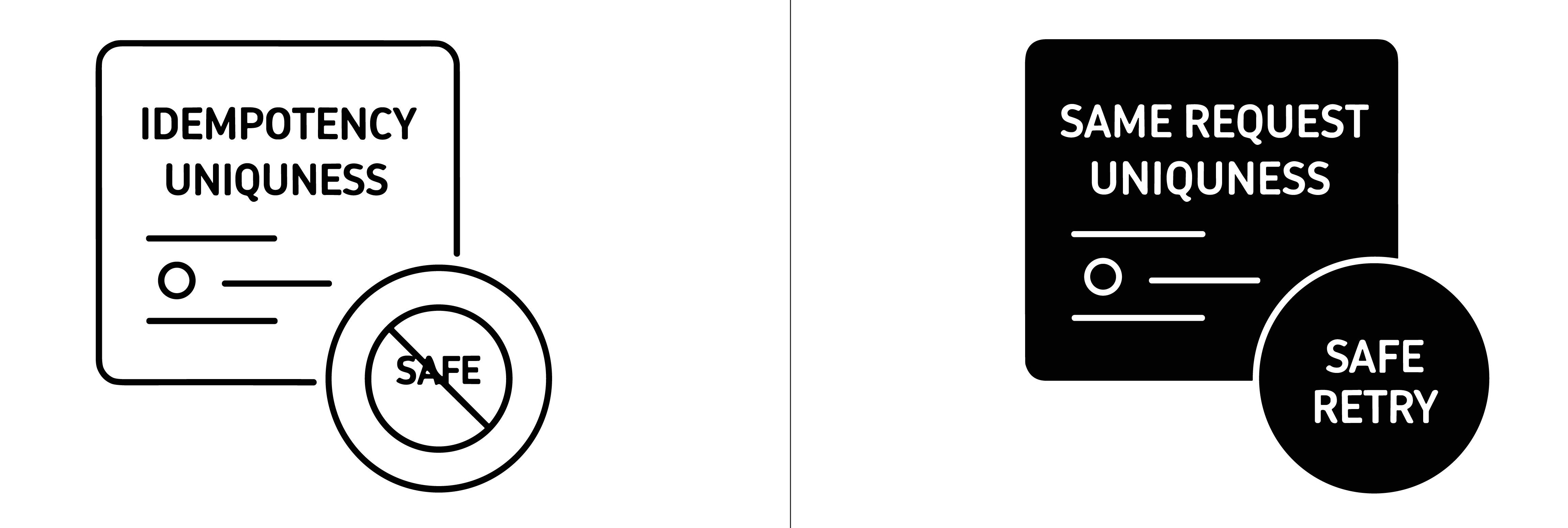
Idempotency means that making the same request multiple times produces the same intended result as making it once. An API that sets an email address is idempotent—repeating it five times leaves one email. An API that adds a balance amount is not—repeating it five times changes the balance five times.
The standard mechanism is an idempotency key: a unique identifier sent by the client with each request. If the same key arrives again, the server recognizes it as a retry and returns the original result rather than executing the operation again. This is especially important when clients cannot confirm whether the first attempt succeeded—when the server processed a request, but the response never reached the client.
A commerce team once built a checkout API without idempotency support. During a payment gateway slowdown, client apps retried after timeouts. The server treated each retry as a new payment attempt. Some customers were charged twice. Refunds were issued manually, support tickets spiked, and trust dropped sharply. The issue was not the retry. It was that the system treated uncertainty as a new command every time. One missing design decision turned a temporary dependency slowdown into a customer-facing incident.
5. Design for Failure, Not for Success
Why Is Designing for the Happy Path Not Enough?
Most systems are designed around the path where everything works: payment succeeds, the network is stable, and every downstream service responds on time. In architecture diagrams, this looks clean.
In production, partial failures are normal. APIs timeout. Queues back up. Third-party services become unavailable. At scale, failure is not an exception—it is a routine operating condition.
A feature that works only when all dependencies are healthy is not production-ready.
How Do You Design a System That Fails Safely?
Designing for failure starts by identifying every point that can break, then defining explicitly how each failure is handled.
Common failure points include:
- External API calls and payment gateways
- Database reads and writes under load
- Cache layers and CDNs
- Message brokers and background workers
- Deployment pipelines and health checks
Core techniques for safe failure design:
| Technique | What It Protects Against |
|---|---|
| Timeouts | Threads blocked indefinitely on slow dependencies |
| Retries with exponential backoff | Accidental surge on a struggling service |
| Circuit breakers | Cascading failures across services |
| Bulkheads | One failure consuming all shared resources |
| Dead-letter queues | Silent message loss in async flows |
| Graceful degradation | Full outage when a non-critical dependency fails |
| Idempotency | Duplicate side effects from retries |
| Observability (logs, metrics, traces) | Silent failures with no visibility |
The deeper principle is this: the system should fail predictably and safely, not just avoid failure.
What Does Failure-Aware Design Look Like in Practice?
An e-commerce checkout assumed the payment gateway would always respond immediately. During a sale event, the gateway began timing out.
Without failure design:
- The checkout service retried aggressively
- Threads were exhausted
- Orders were stuck in unknown states
- Some customers were charged without order confirmation
- A payment dependency issue became a full checkout outage
With failure design:
- Request timeouts would have capped thread exposure
- Idempotency keys would have made retries safe
- A "payment pending" state would have kept orders consistent
- Asynchronous reconciliation would have resolved edge cases in the background
Success paths prove a feature works. Failure paths prove a system is ready for production.
Why These Design Principles Compound Over Time
These five principles are not independent rules. They reinforce each other.
- Strong abstractions make behavior easier to compose
- Composition keeps systems changeable as requirements evolve
- Immutability reduces the surface area where mutations create unexpected side effects
- Idempotency makes distributed systems safe to retry
- Failure design ensures that when any of these layers break, the system degrades predictably
The difference between a codebase that accelerates delivery and one that resists it is rarely one large architectural decision. It is the cumulative effect of smaller, repeated design choices made with these principles in mind.
The best systems are not the ones built fastest. They are the ones still being extended confidently three years later—by engineers who were not in the room when the first line was written.
Explore our Engineering Services and Application Development practice.


Using Affinity Diagramming in Collaborative Analysis and Enterprise Design Workshops



