Permission-aware RAG: the trust layer beneath enterprise generative AI

Roughly 80% of enterprise data is unstructured and the moment you index it for AI, a dozen separate permission models collapse into a single searchable surface.
The model is now the easy part. What decides whether enterprise generative AI is safe to deploy is whether it only ever surfaces what each user is already cleared to see, grounds every answer in a source of truth, and runs where your data is allowed to live. Permissions are where most of that quietly succeeds or fails.
The reason this matters is that the model itself has become a commodity. General-purpose models from a handful of providers are converging on similar capabilities, and any single one's advantage tends to last months. The durable advantage sits in your data and in the engineering that makes it usable, retrievable with permissions intact, truthful, and contained. That layer is harder to build than a demo and harder to copy than a model choice. It is also where a generative AI programme earns trust or loses it.
The leak nobody planned for
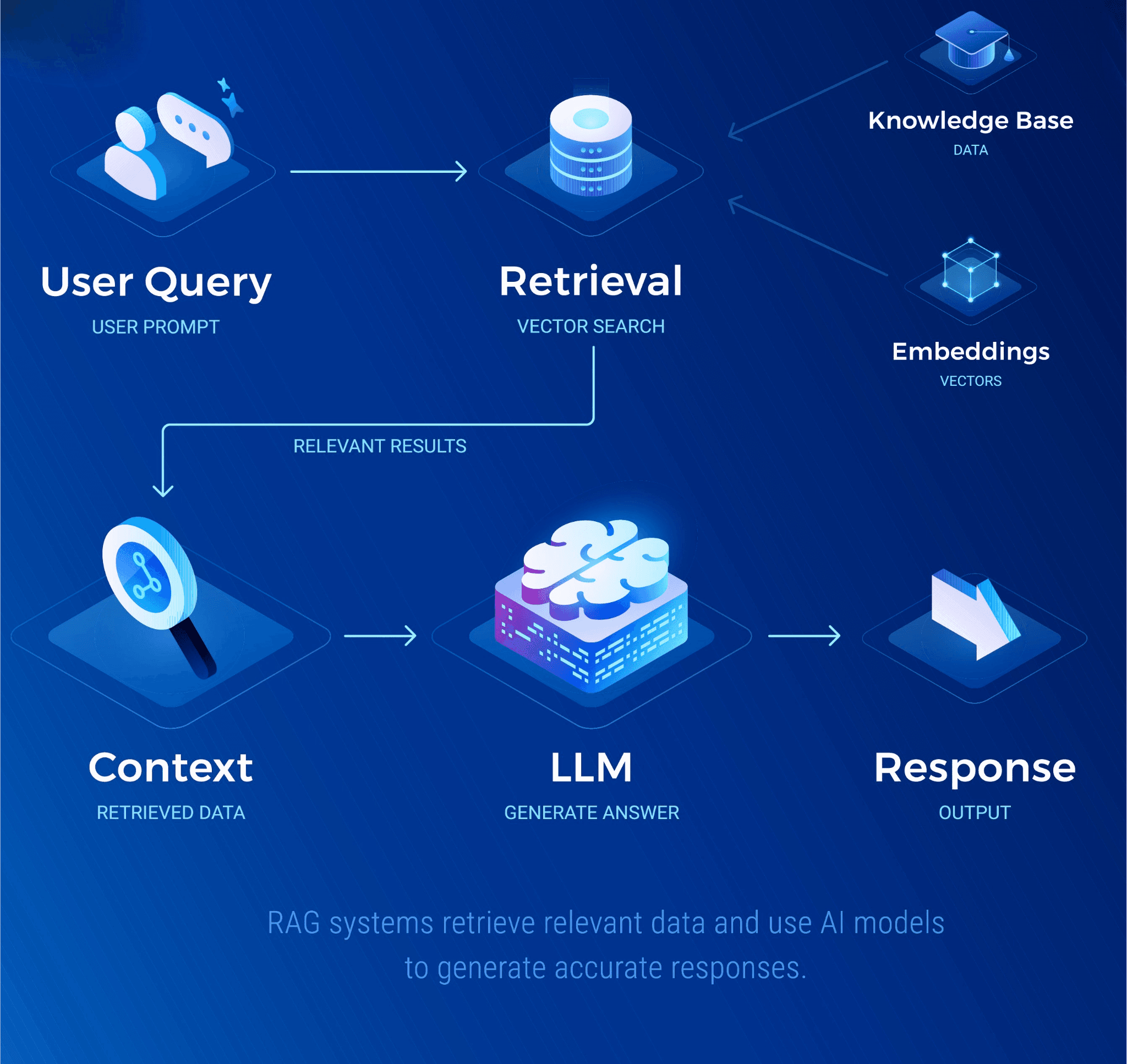
The standard way to give a model knowledge of your business, without retraining it, is retrieval-augmented generation (RAG): at the moment of a query, you retrieve relevant passages from your own content and hand them to the model as grounding, so the answer reflects your reality rather than a generic average of the internet. RAG is now the default pattern for enterprise generative AI.
The moment you index Confluence pages, shared drives, CRM records, HR files, and meeting notes into one searchable store, you have merged a dozen separate permission models into a single retrieval surface. A support engineer who can read customer tickets but not salary bands, and a junior analyst who can see public dashboards but not board papers, now query the same index. Without deliberate controls, the model can retrieve, summarise, and confidently present material the person was never entitled to. The system becomes a back door around the access boundaries your business already runs on.
This is the case for permission-aware RAG: retrieval that enforces each user's access rights so the model only ever sees what that user is cleared to see.
Where the control sits decides whether it works
The single most important design decision is where permissions are enforced, and it is where many implementations quietly go wrong.
The tempting shortcut enforces access in the application layer. The system runs the vector search with no filter, retrieves the most relevant passages, then discards the ones the user is not allowed to see before composing the answer. The problem is that the confidential content has already left the store and entered the pipeline. A single gap in that post-filter, a logging line, an error path, a prompt that quotes a discarded chunk, leaks it. You are guarding the exit rather than the vault.
The robust pattern enforces access in the retrieval layer itself. The user's identity and entitlements are applied as a filter on the vector query, so the search only ever returns passages that person is permitted to read. Nothing the user cannot see is retrieved in the first place, which means nothing unauthorised can reach the model, the logs or the answer. The security boundary lives with the data, not with the application code wrapped around it.
In practice that means attaching access metadata to every chunk at indexing time and filtering against it on every query, so retrieval and authorisation are a single operation rather than two.
| Application-layer filtering | Retrieval-layer filtering | |
|---|---|---|
| Where access is enforced | After retrieval, in application code | Inside the vector query itself |
| What the search returns | All relevant passages, including unauthorised ones | Only passages the user is entitled to |
| Confidential data | Already in the pipeline before it is filtered out | Never retrieved in the first place |
| Typical failure mode | A gap in the post-filter — a log line, an error path, a quoted chunk — leaks data (fails open) | A misconfigured filter returns too little, not too much (fails closed) |
| Audit trail | Harder: unauthorised data has touched the system | Clean: every retrieval is tied to an entitlement |
| Upfront effort | Lower, but the risk is carried into production | Requires access metadata at indexing and filtered queries |
| Suitable for regulated data | No | Yes |
Inheriting the access model you already run
Doing this across a real enterprise is not a toggle. The data lives in dozens of systems with overlapping, inconsistent policies, and the AI has to respect all of them at once.
That means reconciling different authorisation models. Role-based access control (RBAC) grants access by a user's role; attribute-based access control (ABAC) decides by attributes such as department, project, clearance or region. Most enterprises run both, inconsistently, across systems that were never designed to agree with one another. A permission-aware system has to honour each source's rules without flattening them into one lossy model.
The strongest designs validate entitlements against the source systems' own identity and access management in as close to real time as the architecture allows, rather than copying permissions into the AI layer where they immediately start to drift. The practical payoff is revocation: when someone's access is withdrawn in the source system, the AI honours it on the next query rather than continuing to surface what that person can no longer open. And because every retrieval is tied to an identity and an entitlement, the same audit trail that governs your systems extends to every answer the model gives.
This is squarely an enterprise integration problem before it is an AI one. The model is the last component in the chain. The work that makes it safe is the connective tissue that lets it inherit, rather than dissolve, the governance you already have.
Permissions only hold if the data underneath is usable
Access control assumes there is well-organised data to control. For most enterprises there isn't, yet.
By the most widely cited industry estimate, roughly 80% of enterprise data is unstructured: PDFs, contracts, emails, scanned forms, transcripts, images. A model cannot reason over any of it raw, and retrieval cannot enforce permissions on content that has not been properly prepared and labelled. Before generative AI can touch it, that content has to be parsed out of its formats, chunked into passages that keep their meaning, converted into embeddings and indexed in a vector database, with entities and access metadata attached so a query can be both scoped and authorised.
None of this works on data you cannot trust. A retrieval system built over duplicated, stale or mislabelled content will surface the wrong passage, and worse, will attach the wrong permissions to it. Integrity, lineage and validation are the precondition for safe retrieval, not a clean-up task you do later. Putting that foundation in place is the work Tarento's DataVolve practice exists to do, because permission-aware retrieval is only as reliable as the labelling beneath it.
The answer still has to be true
Even with the right passage retrieved and the right permissions enforced, the model can still get the answer wrong. Grounding in your own data substantially reduces hallucination; it does not eliminate it. Models can introduce a claim the source does not support, even when handed the correct source. The best models on grounded tasks now sit in the low single digits for this, but in a financial statement or a compliance answer the residual is exactly the part that hurts.
The defence is to treat truthfulness as something you engineer: cross-reference output against the retrieved sources before it reaches the user, require citations so every material claim points back to an internal document a person can open, and keep human oversight on consequential decisions. We covered the wider risk picture, including prompt injection and data leakage, in our piece on the hidden risks of enterprise LLMs; the point here is that permission-aware retrieval and source-grounded answers are two halves of the same trust layer.
Decide where the models and the data live
The last question is architectural, and it is where data residency meets cost. The reflex is to route everything through the largest external model available. For much enterprise work that is neither the cheapest nor the safest choice.
A smaller model, fine-tuned for a narrow task can match or beat a large general-purpose model on that task while costing far less per query, often by an order of magnitude at volume. Just as important, a compact model can run inside your own security perimeter, on-premises or in a private cloud or VPC, so sensitive and regulated data never leaves your environment. For finance, healthcare and the public sector, where data residency and sovereignty are non-negotiable, that is frequently the deciding factor, and on-premises inference has grown sharply as enterprises move regulated workloads off third-party APIs. The sound design is usually a hybrid: depersonalised work can use an external model where its breadth helps, while sensitive data and high-volume tasks run on internal models behind your own walls, decided deliberately per use case.
How Tarento approaches it
The pattern we follow connects these parts into one trustworthy system rather than four disconnected projects. We establish trustworthy, well-labelled data through DataVolve before anything is indexed. We design permission-aware retrieval that inherits the access controls your business already enforces, so the AI cannot become a route around your own governance. We build in grounding and validation so output is checked against internal sources, and every consequential claim is traceable. And we help you decide where models and data should live, including fine-tuned internal models and on-premises or VPC deployment where residency and cost demand it, integrated into the systems you already run.
This is where Indian engineering depth meets Nordic discipline, and where traceability and restraint are how we build by default. Plenty of vendors will sell you a model. The harder, more valuable job is the trust layer that lets you stand behind what it says.
Frequently asked questions
- What is permission-aware RAG?
Permission-aware RAG is a retrieval-augmented generation that enforces each user's access rights during retrieval, so a model only ever sees and summarises content that the person is already cleared to view. Critically, the control is applied in the retrieval layer, filtering the vector search against the user's identity and permissions, rather than retrieving everything and filtering afterwards, which risks leaking sensitive passages into the pipeline.
- Why is application-layer access control risky in RAG?
Because by the time the application filters results, the confidential content has already been retrieved and entered the pipeline. Any gap in that post-filter, a log line, an error path, or a quoted chunk can expose it. Enforcing access at the retrieval layer means unauthorised passages are never returned at all, so they cannot reach the model, the logs or the answer.
- How does permission-aware RAG handle RBAC and ABAC together?
It honours both without flattening them. Role-based access control grants access by role; attribute-based access control decides based on attributes such as department, region, or clearance. A robust design attaches the relevant access metadata to each indexed chunk and, ideally, validates entitlements against the source systems' own identity and access management in real time, so permissions stay correct, and revocations take effect immediately.
- Does RAG stop large language models from hallucinating?
It reduces hallucinations considerably by grounding answers in your own data, but does not remove it. Models can still introduce or contradict claims even when given the correct source. Reliable systems cross-reference output against retrieved sources, require citations to internal documents, measure faithfulness over time, and keep human oversight on high-stakes decisions.
- Should an enterprise use a large external model or a smaller internal one?
It depends on the task. A smaller model fine-tuned for a specific, repeatable job can match or beat a large general-purpose model at a fraction of the cost and can run inside your own security perimeter for data residency. Large external models earn their place on broad, open-ended work. Most enterprises are best served by a deliberate hybrid, decided use case by use case.
Ready to build generative AI you can stand behind?
If you are putting generative AI onto your own data and need it to be governed, grounded and safe to act on, that is the work we are built for. Explore Tarento's services, and let us talk about getting the trust layer right before the build begins.


Tarento: A Premier Delivery Partner for Infor ERPs



